Employing a smart city signal at intersections helps smoother navigation in urban areas. Enabling optimized traffic lights is possible in scale by leveraging computer vision techniques such as object detection. We use YOLOv8 for tracking vehicles by type per lane. Additionally, we estimate speed and waiting times at intersections for deeper analysis and insights. Interactive-OR Lab Keywords: Computer Vision, YOLOv8, Object Detection
Parking Lot Occupancy Detection
Finding convenient parking is difficult in cities where occupancy information is unavailable. We use YOLOv8, a computer vision object detection model provided by Ultralytics, to detect the occupancy status of individual parking spaces in a lot. We display parking spaces as polygons and use red and red to represent empty and occupied spaces, respectively. The real-time detected occupancy of the lots is then aggregated and displayed on a web app accessible to all. Interactive-OR Lab Keywords: Computer Vision, YOLOv8, Object Detection
On-street Parking Occupancy Detection
We developed an approach to parking demand data collection that leverages dashcams on moving bikes. We begin by geofencing existing on-street parking zones based on the Toronto Parking Authority’s Green-P zones. We then use object detection models to detect vehicle presence when a bike crosses the designated fence and enters the parking zone. Every time a parking zone is visited, the occupancy ground truth is revealed. Therefore, the occupancy prediction accuracy improves with the number of visits per parking zone. The data is subsequently analyzed and visualized on a GIS-based tool to enhance data-driven parking policy decision-making, such as pricing and enforcement. This project was presented at ITE Canada 2024 Conference. Interactive-OR Lab Keywords: Computer Vision, YOLOv8, Object Tracking
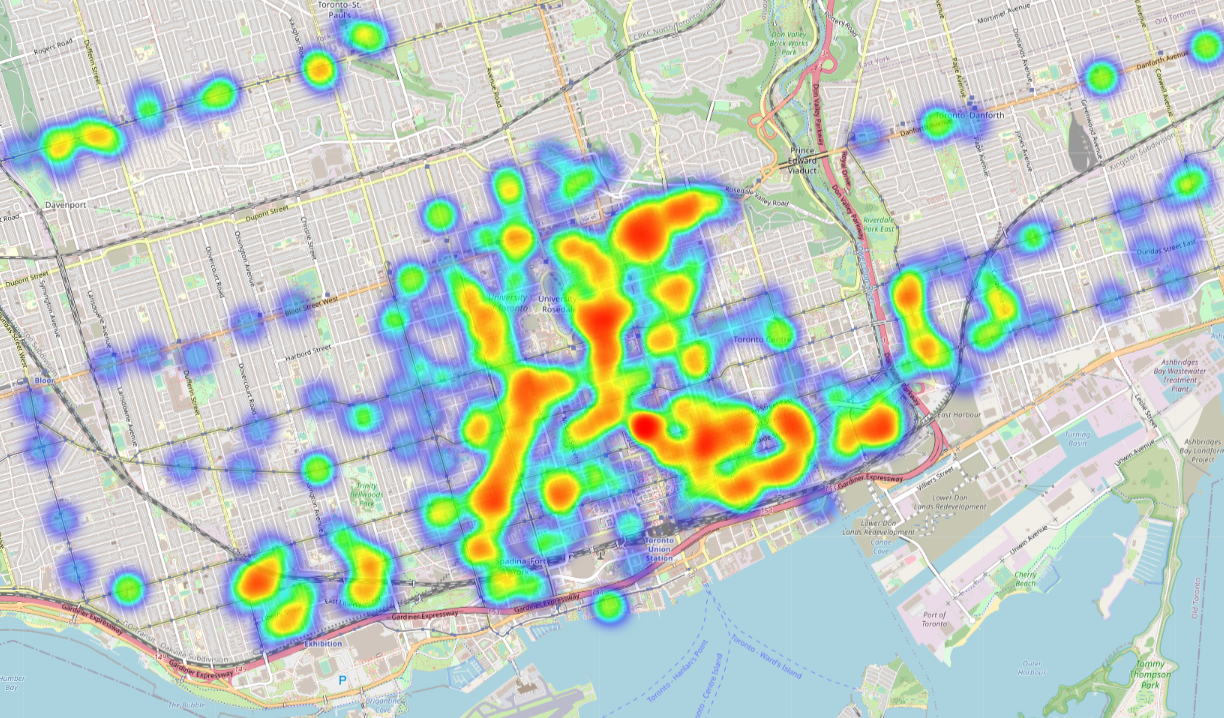
Parking Violations
We've meticulously gathered data publicly available from the City of Toronto's open data platform, focusing on on-street parking dynamics. This extensive dataset encompasses transactional records of parking space usage, amenities in proximity to these areas, and reported violations leading to ticket issuance. Our primary objective is to employ cutting-edge models, including Graph Neural Networks and Gradient Boosted Trees, to predict instances and locations where parking violations are more likely to occur. This innovative study holds the potential to significantly contribute to the city's urban planning efforts by shedding light on patterns and trends related to parking violations. This project was presented at ITE Canada 2024 Conference. Interactive-OR Lab Keywords: Graph Neural Network, Gradient Boosted Trees, Urban Planning Insight
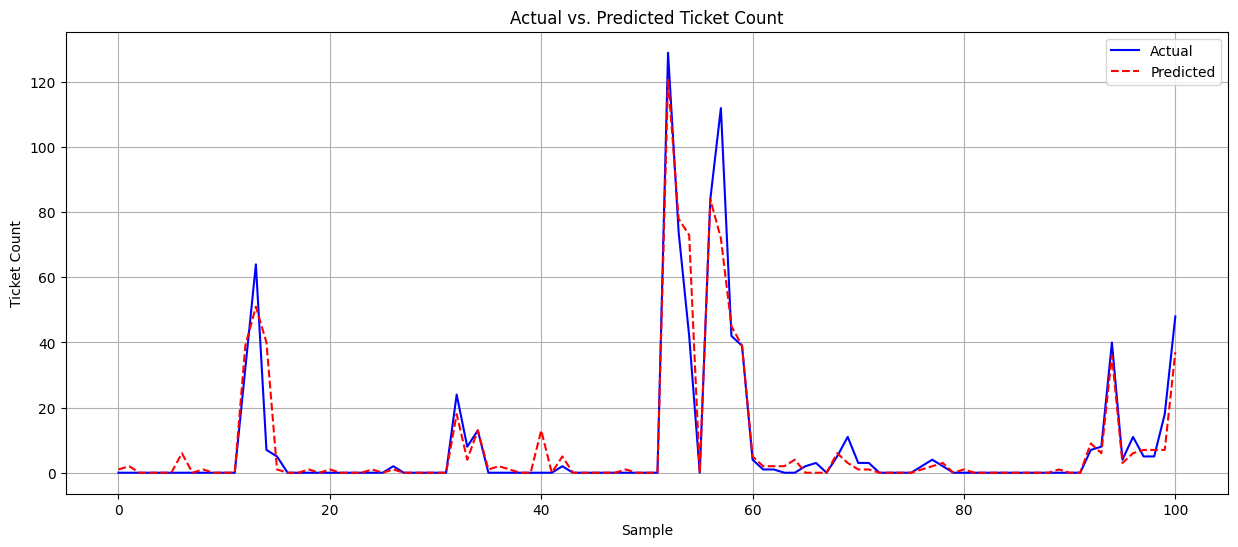
RankLib Gini Feature Importance
Ranklib offers a valuable feature management tool, generating insightful feature usage statistics. These statistics unveil the frequency of each feature’s utilization within the learning to rank model. However, it’s essential to recognize that the frequency of a feature does not necessarily correlate with its importance or effectiveness. In response to this, I have developed a specialized program to calculate the Gini importance of features in RankLib’s random forest model. The Gini importance metric is widely acknowledged and utilized in learning to rank research as a reliable criterion for determining the most impactful features. My program is available in this GitHub repository. Laboratory for Systems, Software and Semantics Keywords: Gini Feature Importance, RankLib, Learning to Rank, Random Forests
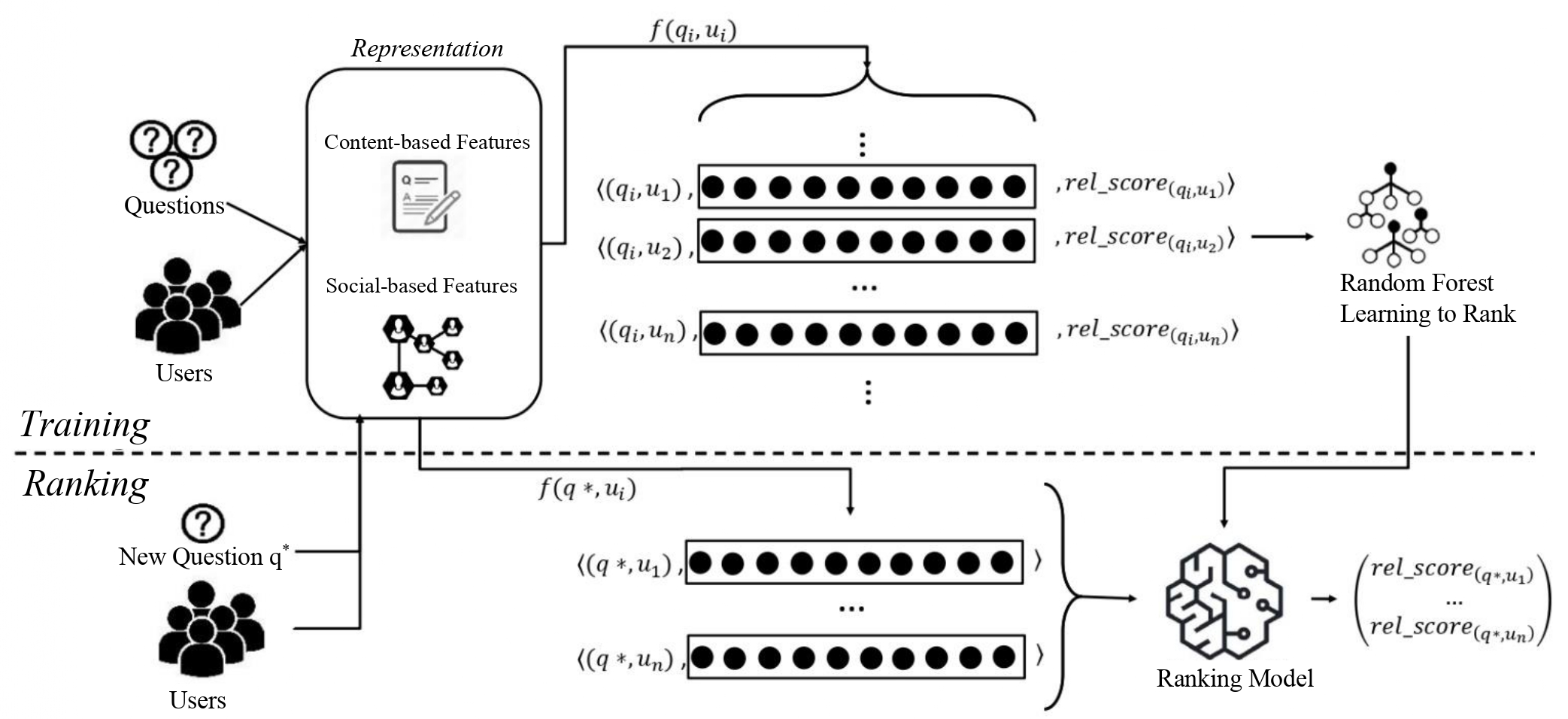
Question Routing in Community Question-Answering Platforms
The success of community question-answering (CQA) platforms, such as Stack Overflow and Quora, is dependent on how efficiently new questions are assigned to community experts, known as question routing. We developed an expert recommending system for CQA platforms. We defined 74 features using techniques such as LDA topic modeling, word mover’s distance text similarity, and graph embedding. We optimized the features through feature engineering and proposed a learning to rank approach that achieved 16.41% higher performance than the deep learning state-of-the-art model in NDCG@10 on 5 websites’ datasets. We used a transparent and interpretable model and provided insights on the most important and effective features. The result is published as a journal paper and can be found here. Laboratory for Systems, Software and Semantics Keywords: Question routing, Expert finding, Embedding, Learning to rank, Multimodal Representation